
Partie 9 : Découper le stockage des tables en pages
Lecture 5 min. •
Table des matières
Les articles de la série
- Partie 1 : Construire le REPL
- Partie 2 : Sérialisation des données
- Partie 3 : Database
- Partie 4 : Tables
- Partie 5 : Parser les commandes, création de la boîte à outils
- Partie 6 : Parser les commandes SQL
- Partie 7 : Tuples de données
- Partie 8 : Contraindre les données via un schéma
- Partie 9 : Découper le stockage des tables en pages
- Partie 10 : Clefs primaires
- Partie 11 : Expressions Logiques SQL
- Partie 12 : Scans et filtrage
- Partie 13 : UTF-8 et caractères échappés
- Partie 14 : Attributs nullifiables
- Partie 15 : Index secondaires
- Partie 16 : Directive EXPLAIN
- Partie 17 : Logical Plan
- Partie 18 : Exécution du plan logique
- Partie 19 : Suppression d'enregistrements
- Partie 20 : Réindexation et compactation de tables
Bonjour à toutes et tous 😃
Petit article (en comparaison des autres 😅).
Bien que l’on soit en train de réimplémenter tout et n’importe quoi pour notre plaisir et notre apprentissage à la fois dans Rust et dans la création de base de données.
Notre objectif est de créer un sqlite, et qui dit sqlite, dit persistance sur disque.
Pour le moment, toutes nos opérations sont in-memory, on peut se permettre de scanner la mémoire pour un coup modique. Même si on a plusieurs centaines de mégaoctets le délais de scan de la table reste acceptable.
Par contre si on commence à stocker sur disque, un problème de taille (et c’est le cas de le dire) va intervenir: lire un fichier est LENT !!
Pour éviter cette lenteur, il faut absolument le “monter en mémoire”, mais on ne va pas monter 2Go de base de données!
La solution est de le découper en plusieurs unité logique que nous allons appeler des pages.
Ces pages seront bien plus petites que le fichier de la base de données et permettront par la suite de faire des opérations de cache très intéressantes. 😎
Ces dans ces pages que nous allons stocker nos données et donc nos tuples.
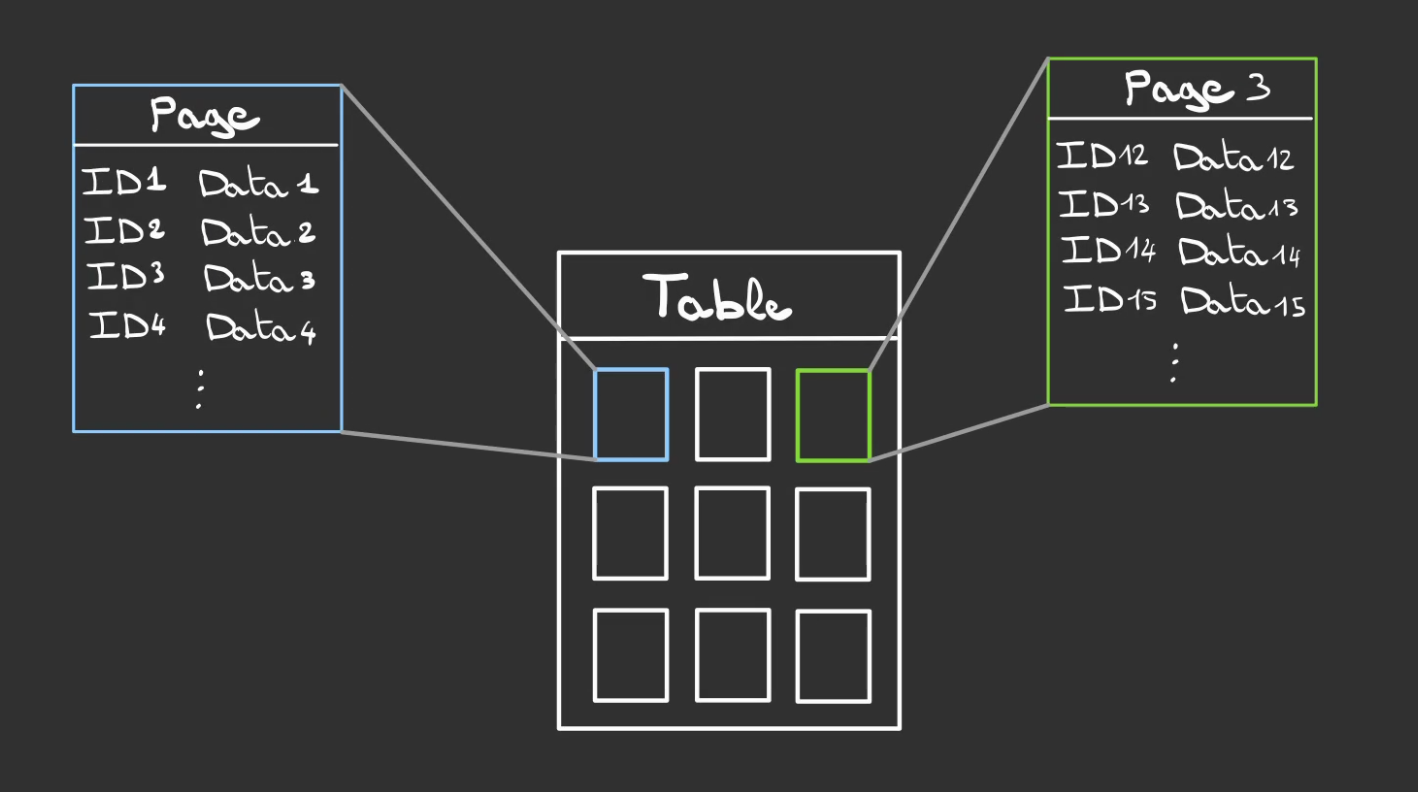
La notion cruciale que nous allons devoir respecter pour espérer récupérer quoique ce soit de page est que chaque données doit avoir rigoureusemet la même taille.
Heureusement, c’est déjà la cas grâce à notre Schéma qui contraint désormais nos tuples à respecter toutes les règles que l’on lui dicte avant insertion des dites données dans la table.
Nous pouvons alors implémenter le trait Size sur le Schéma
Cela est possible car chaque ColumnType connaît très exactement la place qu’il prend. On peut donc sommer ces emplacements pour obtenir la taille du tuple en mémoire.
Nous allons nous retrouver dans cette configuration.
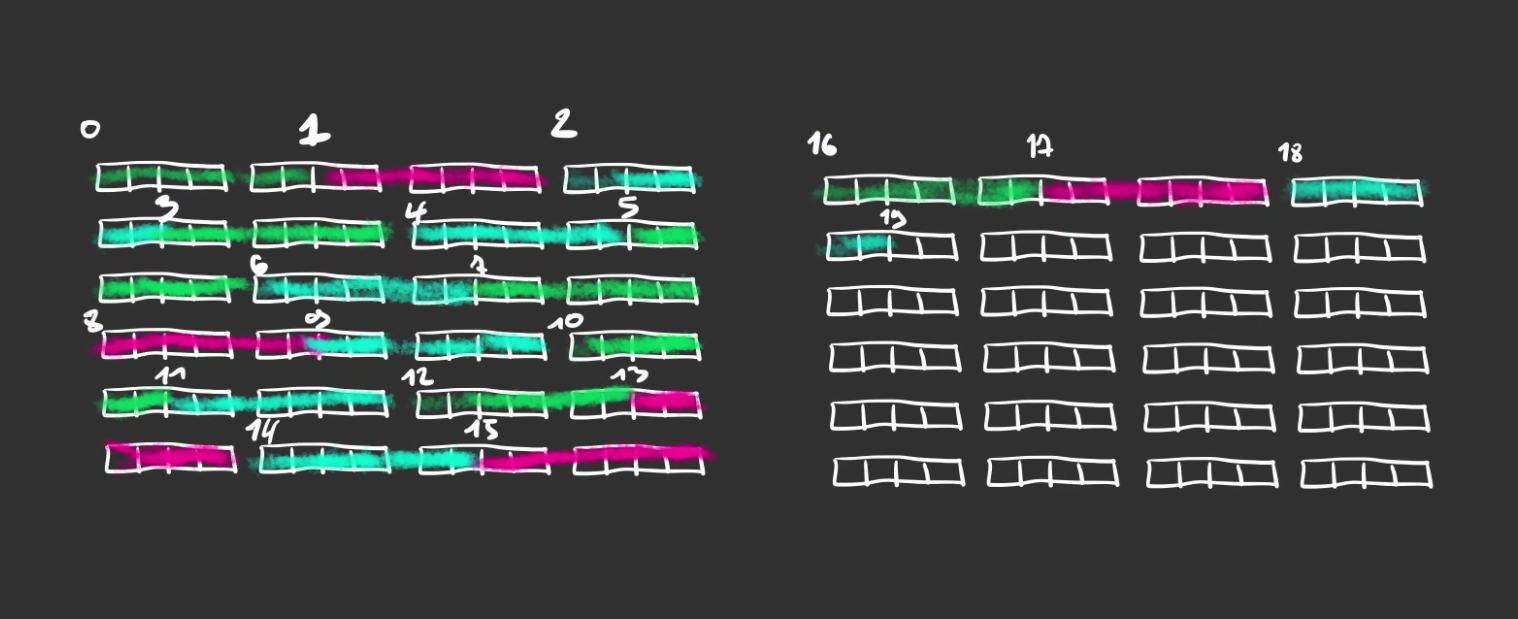
Chaque tuple d’une table prend la même place et on peut alors les sérialiser les uns après les autres.
Ici j’ai représenté deux pages de 96 cases et des tuples de 6 cases.
En faisant la division on se retrouve avec 96 / 6 = 16 tuples stockables dans une page. Le 17ème se trouvant dans la page suivante (on commence à 0 les index).
Mais attention! Si la taille du tuple n’est pas aussi sympathique, comme 7 cases par exemple, nous allons observer un phénomène de fragmentation de la donnée qui se retrouve sur plus d’une page, on nomme ça du désalignement.
En effet 96 / 7 = 13.7.., le 14ème élément va se retrouver coupé en deux.
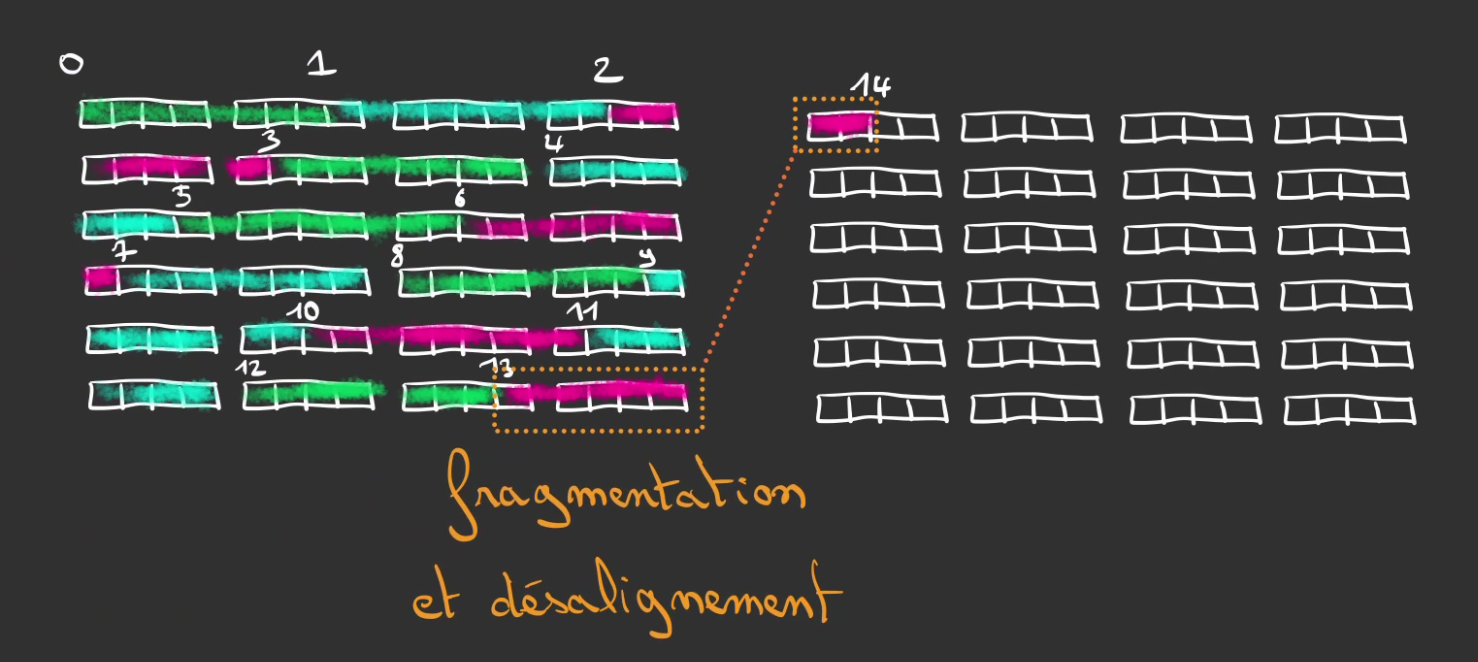
Pour contrer ce phénomène, nous allons condamner les cases qui provoquent ce désalignement.
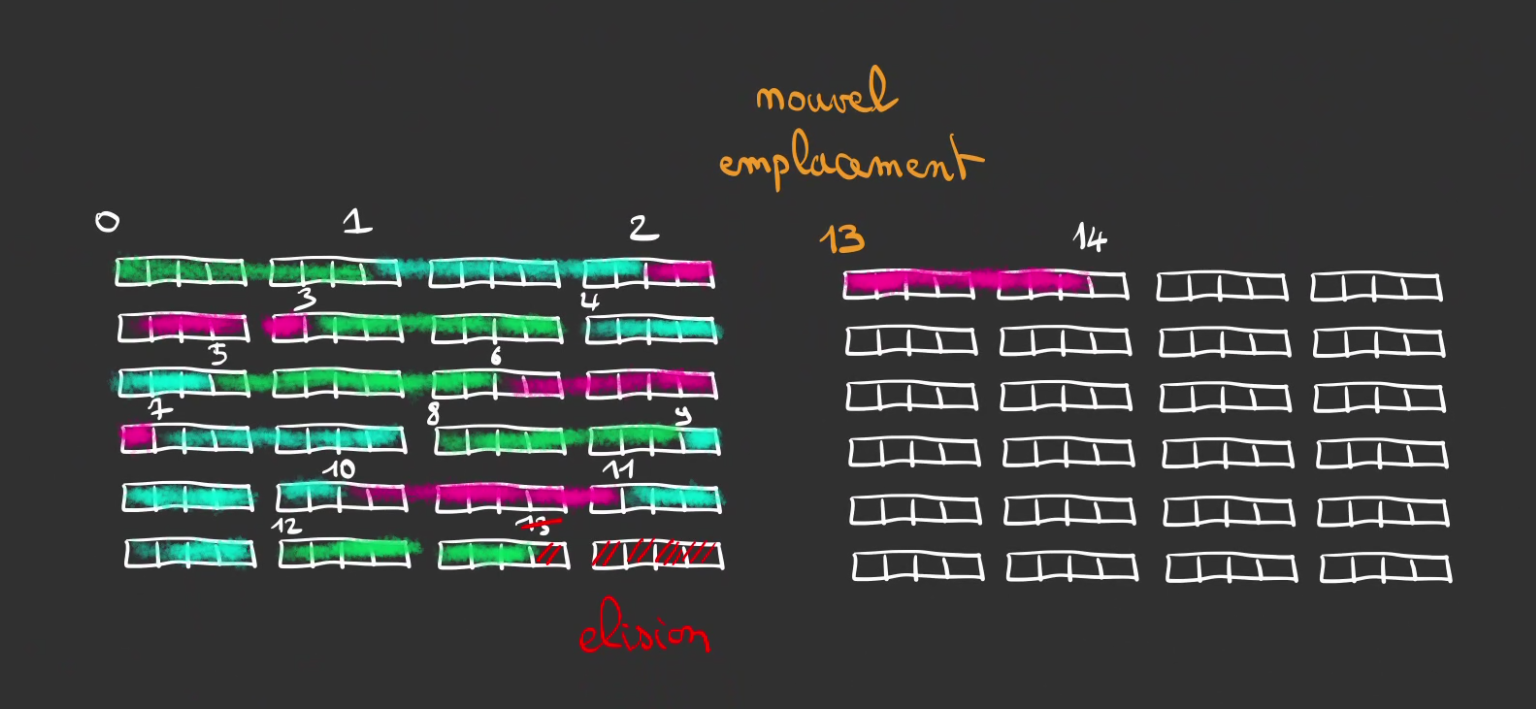
Ainsi, le début 14ème élément est désormais déplacé dans la deuxième page, ce qui résout le désalignement.
C’est bien beau de pouvoir stocker de la donnée dans nos pages, encore faut-il pouvoir les lire après coup.
Pour cela, nous allons utiliser une arme des plus commode : les mathématiques !! 😇
Déjà calculons la taille de la page. Prenons arbitrairement 4096 octets, c’est la taille d’un bloc de données dans plusieurs système de fichier, ça accèlerera les opérations.
Nous l’appellerons en majuscules : PAGE_SIZE.
Pour éviter les désalignements en fonction de la taille du tuple row_size, nous devons tronquer cette taille.
page_size = (PAGE_SIZE // row_size) * row_size
Cela nous donne un page_size en minuscule cette fois.
Attention
Le symbole
//est la division entière, on ne peut pas simplifier “en haut et en bas” parrow_size.
Pour retrouver la position du tuple d’index row_number, il faut d’abord trouver sa page.
page_number = (row_number * row_size) // page_size
^---------------------^
index global
Ce qui revient à mettre à plat toute nos pages tronquées et à définir l’index global dans cette immense tableau, puis à diviser cette index par la taille d’une page tronquée.
Pour trouver la position du tuple dans cette page son offset, on va alors utiliser la même technique, on calcul l’index global global_index, mais cette fois ci au lieu de diviser, on soustrait les tailles de pages qui ne sont pas la page sélectionnée.
offset = global_index - page_number * page_size
En cumulant ces deux informations, il est possible de retrouver notre tuple dans les pages, vive les maths! 🤩
Matérialisons tout ça.
D’abord, on se créé une structure Page qui sera notre page.
pub const PAGE_SIZE: usize = 4096;
Note
Si on demande la taille d’une page, on aura très exactement
4096bytes.
On lui ajoute deux méthodes qui permettent d’accéder en lecture et en écriture à une zone de la page.
On peut maintenant définir un objet Pager qui aura pour rôle de maintenir les pages.
Lors de la création du pager, on y calcule notre fameuse taille tronquée.
On peut alors définir notre méthode qui réalise l’opération mathématique de récupération le page et de son offset.
On défini pour l’occasion une structure de Position
Pour finalement définir deux méthodes qui permettent respectivement de récupérer une slice en lecture et en écriture, positionné au début du tuple demandé.
On peut alors finalement modifier la table pour lui rajouter le Pager et lui retirer la slice de data.
Et finalement utiliser le pager dans nos commandes d’insertions
Et de sélection, pour le moment on déclare une erreur si la page n’existe pas, dans l’avenir on dira que la donnée n’existe pas.
Conclusion
Un article court et globalement technique, les tests unitaires n’ont pas bougé d’un poil car les modifications sont purement internes.
Mais le travail que nous avons faut va nous ouvrir la voie dans les prochaines parties sur plein d’optimisations très intéressantes comme du cache LRU.
Dans la prochaine partie, nous verrons les index primaires et comment récupérer de la données autrement qu’en scannant toute la table !
Merci de votre lecture ❤️